Spark 对分布式计算做了统一的抽象,所以无论是单机或集群模式下,它使用的接口完全一样, 这样就使 Spark 应用可以很容易调试和扩展。
Spark Application
在集群模式下,Spark 使用 master/slave 架构, 中心的协调者被称为 driver,driver 与分散的 worker 进行通信,分散的 worker 又被称为 executor, 这些 driver 和 executor 合称为 Spark Application。
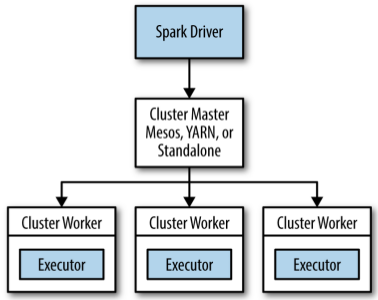
cluster manager
Spark Application 通过一个 cluster manager 启动运行在集群计算机上面, 目前有三种 cluster manager:
- standalone
- Apache Mesos
- Hadoop YARN
spark-submit
无论在何种 cluster manager 下,Spark 统一用 bin/spark-submit 脚本来启动用户程序。
通过不同的参数,spark-submit 可以链接到不同的 cluster manager,控制应用所需资源的大小。
./bin/spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # other options
<application-jar> \
[application-arguments]
其中:
--class: 应用的入口点--master:cluster 的 master URL--deplay-mode:控制是否部署 driver 在本地或在 node 节点上--conf:任意的 Spark 配置选项application-jar:附带的 jar 路径application-arguments:用户程序的参数
standalone cluster
开启 standalone master server:
./sbin/start-master.sh
启动后会输出一个 cluster master url。
开启 standalone worker:
./sbin/start-slave.sh <cluster-master-url>
可以通过一下脚本来控制启动 standalone cluster 的启动和运行:
sbin/start-master.shsbin/start-slaves.shsbin/start-slave.shsbin/start-all.shsbin/stop-master.shsbin/stop-slaves.shsbin/stop-all.sh
这些脚本可以利用 conf/slaves 配置来指定 standalone worker 的地址。