Spark 是什么?
Spark 是一个通用的集群计算框架,通过将大量数据集计算任务分配到多台计算机上,提供高效内存计算。 如果你熟悉 Hadoop,那么你知道分布式计算框架要解决两个问题:如何分发数据和如何分发计算。 Hadoop 使用 HDFS 来解决分布式数据问题,MapReduce 计算范式提供有效的分布式计算。 类似的,Spark 拥有多种语言的函数式编程 API,提供了除 map 和 reduce 之外更多的运算符, 这些操作是通过一个称作弹性分布式数据集(resilient distributed datasets, RDDs)的分布式数据框架进行的。
本质上,RDD 是一种编程抽象,代表可以跨机器进行分割的只读对象集合。 RDD 可以从一个继承结构(lineage)重建(因此可以容错),通过并行操作访问, 可以读写HDFS或S3这样的分布式存储,更重要的是,可以缓存到 worker 节点的内存中进行立即重用。 由于 RDD 可以被缓存在内存中,Spark 对迭代应用特别有效,因为这些应用中,数据是在整个算法运算过程中都可以被重用。 大多数机器学习和最优化算法都是迭代的,使得 Spark 对数据科学来说是个非常有效的工具。 另外,由于 Spark 非常快,可以通过类似 Python REPL 的命令行提示符交互式访问。
Spark 库本身包含很多应用元素,这些元素可以用到大部分大数据应用中。 Spark 核心是一个“计算引擎”,用来调度、分发、集群监控。 由于 Spark 很快,在其之上有许多组建,其中包括对大数据进行类似 SQL 查询的支持,机器学习和图算法,甚至对实时流数据的支持,等等。
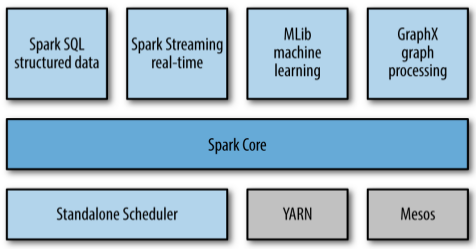
Spark Core:包含了 Spark 的基本功能(任务调度、内存管理、故障恢复、与存储系统的交互等等),也定义 RDD 的相关 API。 其他 Spark 的库都是构建在 RDD 和 Spark Core 之上的。Spark SQL:提供通过 Apache Hive 的 SQL 变体 Hive 查询语言(HiveQL)与 Spark 进行交互的 API。 每个数据库表被当做一个 RDD,Spark SQL 查询被转换为 Spark 操作。Spark Streaming:允许对实时数据流进行处理和控制,允许程序能够像普通 RDD 一样处理实时数据。MLlib:一个常用机器学习算法库,算法被实现为对 Spark RDD 的操作。这个库包含可扩展的学习算法,比如分类、回归等需要对大量数据集进行迭代的操作。GraphX:控制图、并行图操作和计算的一组算法和工具的集合,扩展了 RDD API,包含控制图、创建子图、访问路径上所有顶点的操作。Cluster Managers:Spark 可以运行在许多集群管理器上,从而可以很容易的扩展到成千上万的计算节点。
安装
目前 Spark 最新版本是 2.0.0,所以本篇及其后系列文章均基于此版本,API 调用基于 Python 语言 。
由于 Spark 是由 Scala 语言开发的,运行在 Java 虚拟机上, 所以你的计算机上需要安装 Java,如果要使用 Python API,也需要安装 Python。
下载:
mkdir spark
cd spark
wget http://d3kbcqa49mib13.cloudfront.net/spark-2.0.0-bin-hadoop2.7.tgz
验证:
md5sum spark-2.0.0-bin-hadoop2.7.tgz # verify md5 signature
解压:
tar -xf spark-2.0.0-bin-hadoop2.7.tgz
文件列表
cd spark-2.0.0-bin-hadoop2.7
ls
README.md: Spark 的简短说明,以及一些开启指令bin、sbin: Spark 相关的可执行程序conf: Spark 配置文件文件夹,里面包含了一些示例examples: 运行 Spark 的一些示例license: 与 Spark 相关的开源许可文件data、python、R、...:Spark 主要组建的代码
Spark python shell
./bin/pyspark
默认 python2 交互环境,如果想用 python3:
PYSPARK_PYTHON=python3 ./bin/pyspark
也可以利用 ipython:
PYSPARK_DRIVER_PYTHON=ipython ./bin/pyspark
简单配置
在交互界面下,有许多繁琐的日志输出,要减少它们需要创建 conf/log4j.properties 文件:
cp conf/log4j.properties.template conf/log4j.properties
将 conf/log4j.properties 中的 log4j.rootCategory=INFO, console 修改为 log4j.rootCategory=WARN, console。